This whole story starts with a screenshot.
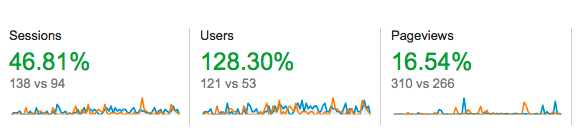
Talk about awesome, right? Huge jump in visitors over the course of a month and I’m rushing to off to call my client and tell him the good news. Seeing as I had been struggling with this site for over 5 months, I was overjoyed when I saw these numbers. I was envisioning praises and pay raises coming my way.
Until I decided to look at what caused this amazing shift in traffic for us. What I saw was this:
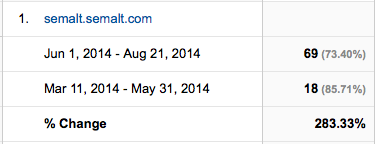
I felt like a Jack the Ripper victim. The color ran from my face and I quickly hung up on the client before he could answer. And then the truth fully dawned on me. Not only did we not see the growth that I had prematurely celebrated but my analytics data was going to be artificially inflated for the foreseeable future. It felt very similar to this gif.

And while I had noticed Semalt hanging around in my client’s analytics data I didn’t think anything of it. It was like a discomforting little twitch that make me say, “What is that thing?”. After this little incident however, it was like a spider bite that had gone untreated. It was inflamed and really pissing me off.
Learn from my mistake and squash this thing before it has a chance to really screw up your analytics data.
What Is Semalt?
According to their website, Semalt is a “professional webmaster analytics tool that opens the door to new opportunities for the market monitoring, yours and your competitors’ positions tracking and comprehensible analytics business information.” In other words a replacement for Google Analytics that is supposedly better as it tracks your competitors’ information as well as your own.
At first glance this seems like a useful tool that could dramatically change how you do business online. A key part of gathering this data comes from the Semalt Crawler, which is a piece of code that scours the Internet and gathers information about every site it can get it’s grubby 8 legs on.
Having it crawl your site doesn’t do any damage and their website says that they won’t distribute your information anywhere online; however, the issue here comes from the way that they have coded the crawler to act as a real visitor. This leads to inflated numbers in analytics and is what lead me to believe this thing needs to be eradicated from my sites.
Let’s Play Pest Control on This Sucker
The first thing you need to know is that the normal remedy for this type of crawler is to add it to your Robots.txt file. This should take care of the problem. But the folks over at Semalt see the Robots.txt file as more of a guideline rather than a rule and so adding it there will do nothing to stop them from crawling your site. This means we need to find other unorthodox methods of giving rid of this thing.
You basically have three options to prevent this crawler from causing further damage to your analytics. While I recommend the most dramatic of these options, if you are unable to access the FTP of your site (or your webmaster won’t do it for you), there are still a couple of ways to lessen the threat this thing poses to your data.
Option 1: Ask Nicely
Semalt does offer an opt-out of sorts on their website. Found here: http://semalt.com/project_crawler.php. However, giving that they don’t exactly follow the rules when it comes to the whole Robots.txt thing, I wouldn’t trust them to stop just because you ask. This is the easiest way to tackle this problem, however, as it doesn’t involved any code or messing around with advanced settings in Analytics.
Option 2: Have Analytics Get Rid of It For You
You can also set up a filter in Analytics to automatically filter out any visits from the website. It’s fairly simple to do as well. Here’s what you need to do:
Step 1: Access the admin panel of analytics.
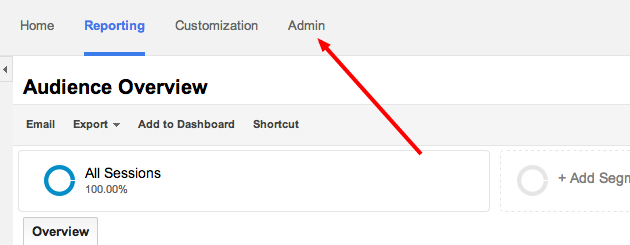
Step 2: Click on Filters under the view column.
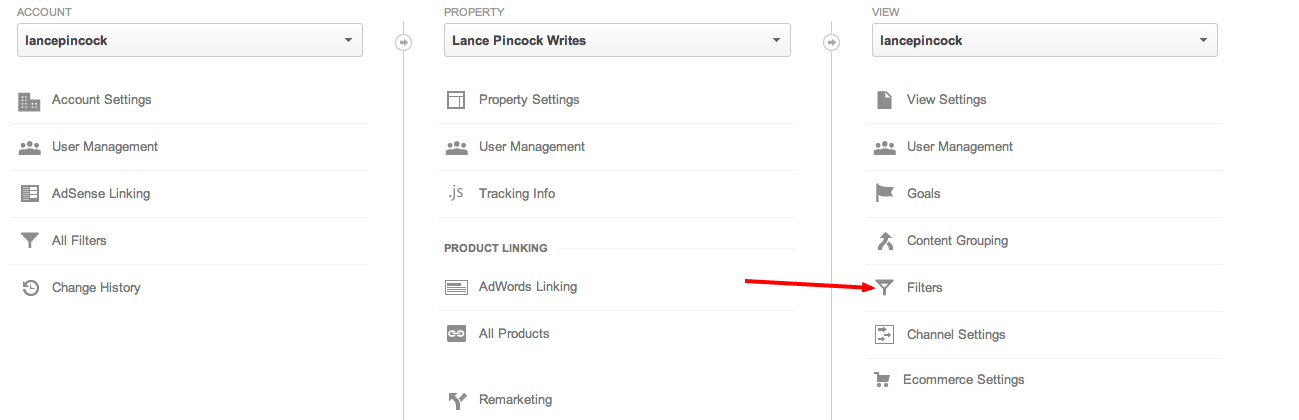
Step 3: Click on Create New Filter.
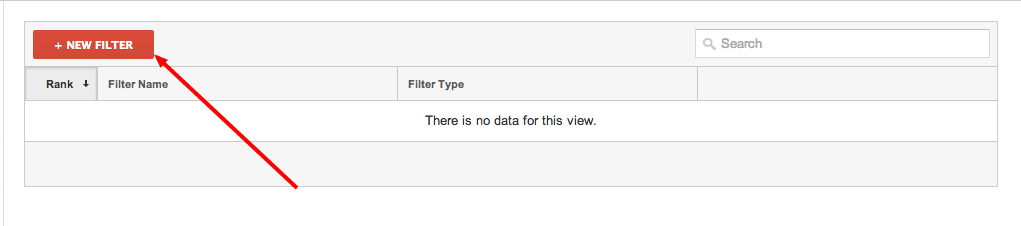
Step 4: Input the following.
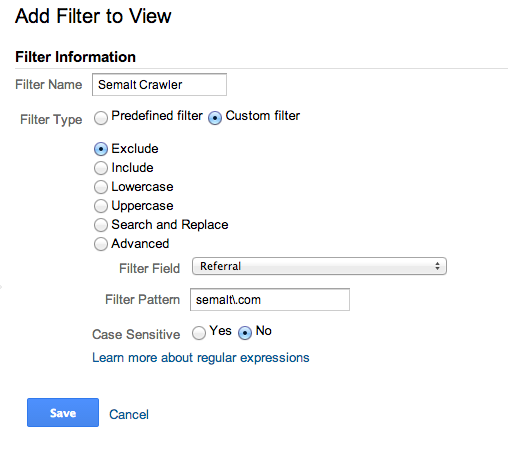
In case you have a hard time reading the screenshot, here are the values you’ll need to input:
- Filter Name: Semalt Crawler
- Filter Type: Custom Filter
- Exclude
- Filter Field: Referral
- (UPDATED: THIS WILL BLOCK ALL SUBDOMAINS)Filter Pattern: (www.|^)semalt.com
- Case Sensitive: No
The (www.|^)semalt.com is a regular expression that will filter all traffic from that domain even if it isn’t coming directly from the root domain of semalt.com.
Once you have those values in, hit save and you are good to go. Be aware however that is method will not remove any data that you have in analytics already and it also doesn’t stop the crawler from accessing your site, it just won’t count any new visits from the site. Because of this, I don’t recommend this method as the crawler can still gather and use your data as it sees fit.
Option 3: Exterminate It Using Htaccess
First you need to access your site via FTP. If you don’t know what that means, I would suggest you either get whoever is hosting your site to help you, or stick with option 2.
If the word htaccess scares you, don’t worry. All we are doing is adding a few lines of code to the bottom of your already existing htaccess file. It’s a copy and paste job that won’t take you more than 5 minutes but will spare you any future heartache over this bug.
Once you are connected to your site via FTP (using a client like Filezilla), locate your htaccess file that should be inside the public html folder and drag it over to your desktop. Then open it in a program like notepad for textedit. Depending on which CMS you are using (wordpress, drupal, etc), you may see a bunch of code in there already. Don’t worry about what is already in there. Simply copy and paste the follow code at the end of the file.
# block visitors referred from semalt.com
RewriteEngine on
RewriteCond %{HTTP_REFERER} semalt.com [NC] RewriteRule .* – [F]
Once you have this code in your htaccess file, hit save and drag the file back to your server via ftp. Make sure to overwrite the old htaccess file with the one you just saved.
This method is preferable because it will completely block Semalt from access your site. Anytime the crawler comes to your site it will be redirected elsewhere and you don’t have to worry about this sneaky bugger gathering any data on you.
Protecting Yourself from Future Crawlers
Sadly, Semalt is just one of the many crawlers out there that scrub the internet for data. Not all of the them are bad. However, if we want to protect our analytics data from future bugs inflating our numbers, we should take steps to block any and all known bad crawlers from our site. Luckily, Google Analytics just launched a new feature that allows us to do just that.
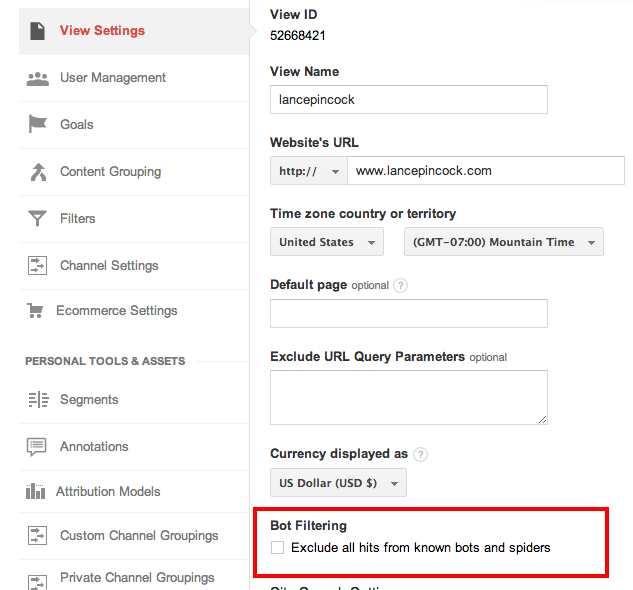
And it’s as easy as ticking a checkbox in your analytics setting. In the same admin panel as before, click on “View Settings” and then just check the “Exclude all hits from known bots and spiders” right under the Bot Filtering section. Here’s a screenshot for you for easy reference.
Regardless of how you feel about crawlers and bots, in order to make good business decisions, you need accurate data. Having inflated analytics data from a rush of crawler hits will continue to skew your numbers for at least a year (when looking at your year over year performance) if not more. Protect yourself.